
L'IA nouvelle chance pour les défenseurs


40 à 62 % du code généré par intelligence artificielle contient des vulnérabilités connues
Auditer son code avec l'IA : entre promesse et désillusion
Les outils d'audit de code alimentés par l'IA promettent de détecter les vulnérabilités avant l'attaquant. La réalité est plus nuancée : faux positifs, économie des tokens et paradoxe du code IA vulnérable imposent une grille de lecture critique. Après avoir exploré la compression du temps d'exploitation côté attaquant, ce deuxième volet examine ce que l'IA change réellement pour le défenseur.
État des lieux de l'arsenal défensif IA
Les progrès technologiques dans la détection automatisée de vulnérabilités marquent un tournant significatif en cybersécurité. En octobre 2024, le projet Big Sleep, fruit de la collaboration entre Google Project Zero et DeepMind, a démontré pour la première fois la capacité d'une IA à découvrir de manière autonome une vulnérabilité réelle et exploitable en production. Il s'agissait d'un débordement de pile dans SQLite, une faille qui avait échappé aux méthodes traditionnelles de détection pendant des années. La percée s'est accompagnée de la découverte de vingt vulnérabilités supplémentaires dans des logiciels critiques comme FFmpeg, ImageMagick et SQLite.
L'affaire Copy-Fail (CVE-2026-31431), révélée début mai 2026, pousse cette logique encore plus loin. Une vulnérabilité présente dans le noyau Linux depuis 2017, exploitable avec un script Python de 732 octets, a été identifiée par l'outil Xint Code en environ une heure de scan. Ce qu'aucun auditeur humain n'avait repéré en neuf ans, un agent IA l'a débusqué en soixante minutes. La rupture d'embargo subie par les failles Dirty Frag (CVE-2026-43284 et CVE-2026-43500) quelques jours plus tôt illustre un corollaire préoccupant : quand la découverte s'accélère à ce rythme, les processus de divulgation coordonnée peinent à suivre, et les défenseurs se retrouvent exposés sans correctif disponible.
GitHub Copilot Autofix représente une autre avancée concrète. Lancé en 2024, cet outil a réduit le temps médian de correction d'une injection SQL de trois heures trente-sept minutes à dix-huit minutes. Entre mai et juillet 2024, les données montrent une réduction du temps de résolution médian passant de une heure trente à vingt-huit minutes. Néanmoins, un petit pourcentage des corrections proposées reflètent une mauvaise compréhension du code ou de la vulnérabilité elle-même.
Snyk DeepCode AI Fix, reposant sur le modèle Mixtral-8x7B, supprime plus de quatre-vingts pour cent des défauts signalés et reproduit exactement la correction humaine entre dix et cinquante pour cent des cas. En limitant l'attention du modèle de langage aux portions de code pertinentes, CodeReduce améliore la précision. Les résultats affichent une réduction du temps moyen de résolution de quatre-vingt-quatre pour cent.
Trail of Bits, engagé dans le défi DARPA AIxCC, a classé au second rang avec vingt-huit vulnérabilités découvertes et dix-neuf correctifs appliqués sur quarante-huit défis. En 2025, l'équipe a fusionné plus de trois cent soixante-quinze demandes de tirage dans plus de quatre-vingt-dix projets open source.
OpenAI Aardvark symbolise l'évolution vers une recherche en sécurité purement autonome. Cet agent analyse les dépôts de code source, identifie les vulnérabilités, évalue leur exploitabilité, établit les priorités de gravité et propose des correctifs ciblés sans intervention humaine constante.
Le mythe de la parité tokens : la cybersécurité comme preuve de travail
L'analyste Drew Breunig a soulevé en avril 2026 une problématique fondamentale souvent occultée par l'enthousiasme technologique. Pour durcir un système via les outils de sécurité IA, les défenseurs doivent acheter davantage de tokens pour découvrir les exploits que les attaquants ne dépenseront pour les exploiter. La dynamique qui en résulte établit un équilibre asymétrique rappelant une preuve de travail.
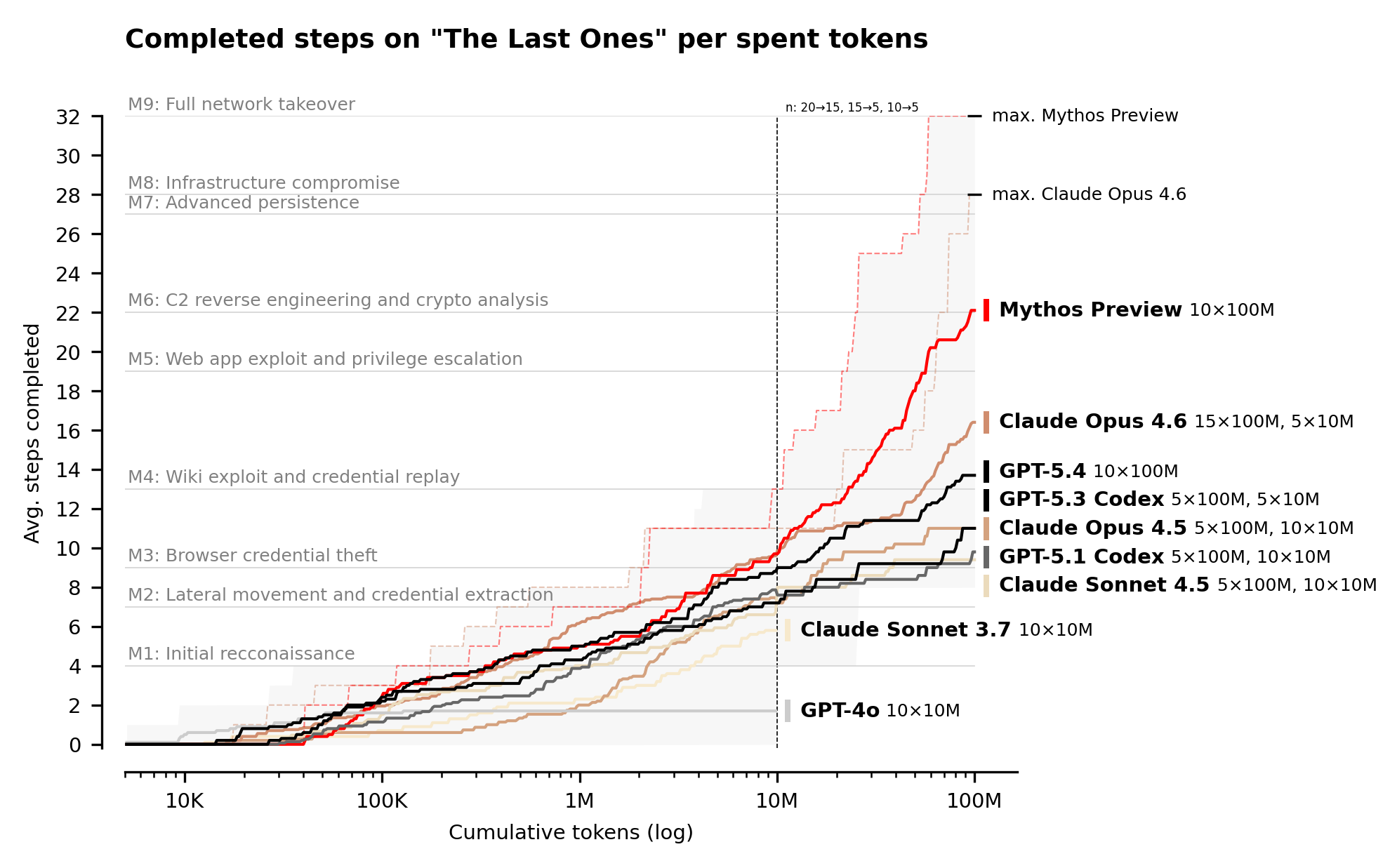
Les modèles disposant de budgets de cent millions de tokens n'ont montré aucun signe de rendements décroissants. Les implications sont profondes pour les organisations aux ressources budgétaires limitées. L'IA élargit le fossé entre les défenseurs bien financés et ceux opérant sous contrainte financière. Le paradigme inversé révèle que l'attaque demeure moins onéreuse que la défense dans l'écosystème des modèles de langage.
Les faux positifs, tueur silencieux de la confiance
Une étude menée en 2024 démontre que trente pour cent des utilisateurs perdent confiance après avoir rencontré à plusieurs reprises des faux positifs. Ce phénomène ébrèche la crédibilité des outils, indépendamment de leur sophistication technique. Historiquement, les systèmes de détection d'intrusion traditionnels générant jusqu'à quatre-vingt-dix-neuf pour cent de faux positifs ont illustré le coût d'une détection imprécise selon un sondage de l'université King Khalid de 2022.
L'IA améliore substantiellement cette équation. Legit Security a démontré une réduction de quatre-vingt-six pour cent des faux positifs dans la détection des secrets, avec un impact négligeable sur les vrais positifs. Cependant, la validation humaine reste essentielle. Les outils IA peuvent signaler des motifs mais ne peuvent valider si ces motifs constituent réellement un risque sécuritaire.
Le paradoxe du code généré par l'IA
Un phénomène troublant émerge des données récentes : les outils qui génèrent du code créent également des vulnérabilités à un rythme alarmant. En novembre 2024, le Centre for Security and Emerging Technology de Georgetown a analysé mille six cent quatre-vingt-neuf programmes générés par GitHub Copilot. Environ quarante pour cent contenaient des vulnérabilités figurant dans la liste MITRE Top 25 CWE.
Une analyse ultérieure sur arXiv en 2025 élève ce seuil à un minimum de soixante-deux virgule zéro sept pour cent de programmes vulnérables. Une étude à grande échelle d'octobre 2025 a compté quatre mille deux cent quarante et une instances de faiblesses communes sur sept mille sept cent trois fichiers attribués à l'IA sur GitHub, couvrant soixante-dix-sept types distincts de vulnérabilités.
Le processus d'amélioration itérative aggrave le problème. Une recherche d'arXiv en mai 2025 révèle une augmentation de trente-sept virgule six pour cent des vulnérabilités critiques après seulement cinq itérations d'« amélioration » sur quatre cents exemples de code. Remédier au code généré par l'IA exige trois fois plus de temps que de corriger du code écrit par des humains.
Les modèles de langage échouent à générer du code sécurisé quatre-vingt-six pour cent du temps pour les failles XSS et quatre-vingt-huit pour cent pour les injections de journal. Un phénomène connexe, le « slopsquatting », s'est manifesté dans une analyse USENIX de Mend.io en 2025 portant sur cinq cent soixante-seize mille échantillons Python et JavaScript. Environ vingt pour cent de ces échantillons référençaient des paquets inexistants, tandis que quarante-trois pour cent des noms de paquets halluccinés se reproduisaient de manière cohérente entre les exécutions du modèle.
Une menace plus subtile apparaît sous la forme du « drift architecturel » : des modifications générées par le modèle qui violent des invariants de sécurité sans transgresser la syntaxe, échappant souvent à l'analyse statique et à l'examen humain. Ces changements semblent bénins sur le plan syntaxique mais fragilisent l'architecture fondamentale du système. Selon un sondage GitHub de 2024, quatre-vingt-dix-sept pour cent des développeurs en entreprise utilisent des outils de codage alimentés par l'IA, ce qui amplifie l'exposition à ces risques.
On ne corrige pas ce qu'on ne comprend pas
L'IA propose des corrections pour du code que les équipes ne maîtrisent pas complètement ou ne comprennent pas. Le risque est celui d'une dépendance technologique : accepter des patches sans en saisir les implications revient à confier les clés de la maison à un serrurier sans vérifier ses antécédents.
L'orchestration de la détection des bugs guidée par l'IA à l'échelle industrielle constitue un défi organisationnel majeur. Gartner rapporte une augmentation de mille quatre cent quarante-cinq pour cent des demandes de systèmes multi-agents entre le premier et le second trimestre 2025. Le marché de l'orchestration IA croît de onze virgule zéro deux milliards de dollars en 2025 à une projection de trente virgule vingt-trois milliards en 2030, soit un taux de croissance annuel de vingt-deux virgule trois pour cent.
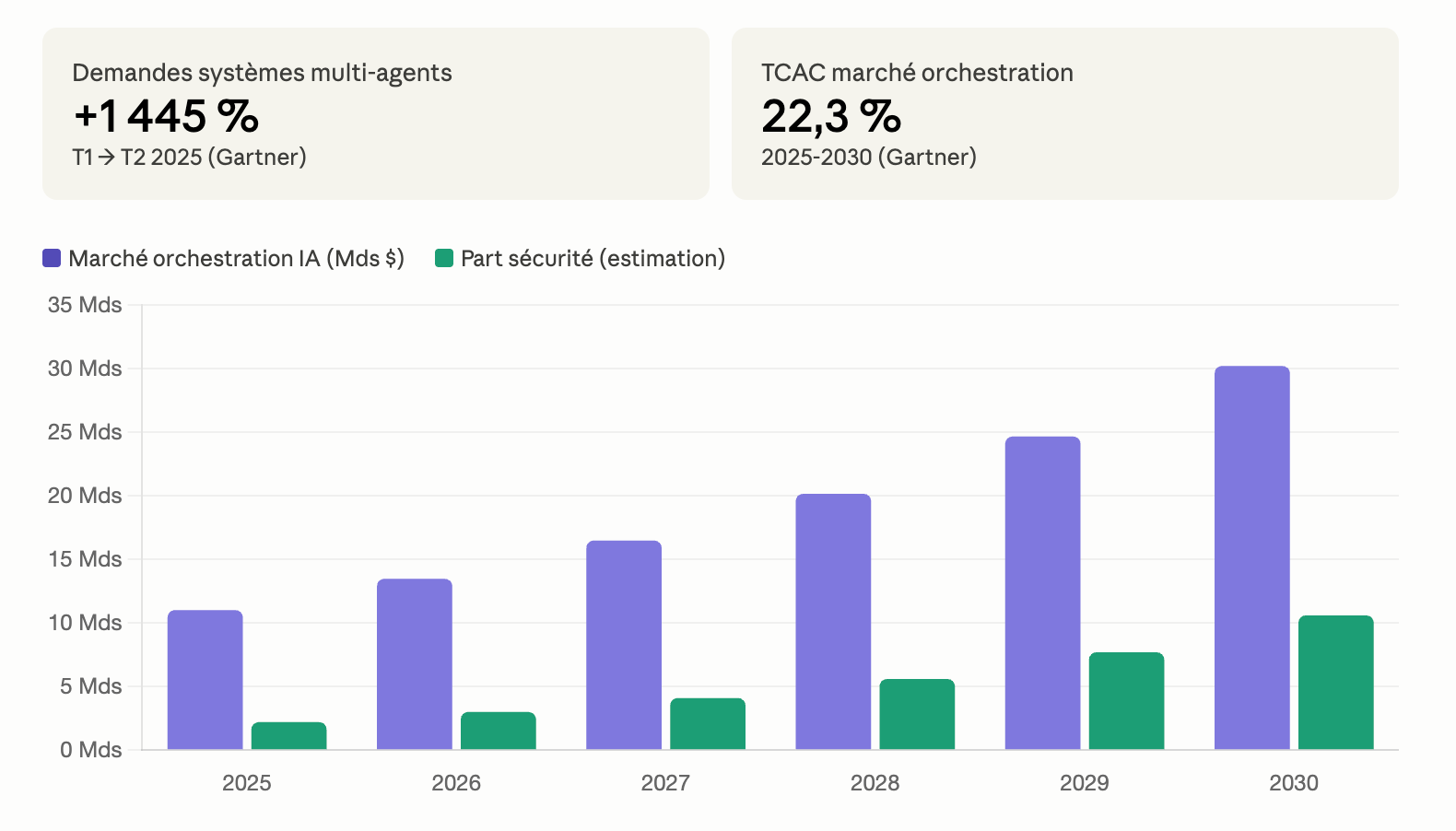
Mais l'expansion technologique masque un défi fondamental : comprendre l'intention du code avant de tenter de le corriger. Automatiser la correction sans cette compréhension introduit des régressions invisibles et des faiblesses latentes.
Recommandations
Intégrer l'IA dans la chaîne de sécurité exige une approche réfléchie et graduée. Les organisations devraient combiner l'expertise IA et l'expertise humaine, en rejetant fermement tout paradigme d'automatisation complète sans validation. Avant de déployer les correctifs proposés par l'IA, il convient d'établir une politique claire de propriété du code, garantissant qu'une équipe définie demeure responsable de chaque modification.
Mettre en place une gouvernance robuste du code généré par l'IA, avec des tests exhaustifs, des révisions de sécurité approfondies et une traçabilité complète, devient impératif. La directive NIS2, et plus largement le Cyber Resilience Act, imposent des obligations de diligence raisonnable sur le code intégré dans les systèmes critiques. Les organisations doivent documenter les origines du code, en distinguant clairement le code humain du code généré par l'IA.
Produire une nomenclature de logiciels (SBOM) explicite pour les composants générés par l'IA facilite le suivi des vulnérabilités. La démarche, empruntée aux meilleures pratiques de gestion des dépendances, s'étend naturellement à la gestion des artefacts d'IA. La transparence quant à l'origine et à la nature du code devient un atout compétitif et un facteur de résilience.
tl;dr
L'IA accélère la détection des vulnérabilités (Copy-Fail, cachée dans le noyau Linux depuis neuf ans, a été débusquée en une heure par un agent IA) mais crée paradoxalement plus de code vulnérable qu'elle n'en corrige. La parité asymétrique des tokens favorise les attaquants munis de ressources computationnelles illimitées, élargissant le fossé de sécurité global. Aucun outil IA, aussi sophistiqué soit-il, ne remplace la compréhension humaine du code et l'intention architecturale. La gouvernance, la validation et la traçabilité constituent le fondement d'une intégration responsable de l'IA en cybersécurité.
Sources
Google Project Zero et DeepMind, Big Sleep, octobre 2024 ; Xint Code, Copy-Fail (CVE-2026-31431), mai 2026 ; Dirty Frag (CVE-2026-43284, CVE-2026-43500), mai 2026 ; GitHub, Copilot Autofix, 2024 ; Snyk, DeepCode AI Fix, 2024 ; Trail of Bits, DARPA AIxCC, 2025 ; OpenAI, Aardvark, 2025 ; Breunig, Drew, The Token Economics of AI-Driven Security, avril 2026 ; CSET Georgetown, Vulnerability Analysis of Copilot-Generated Code, novembre 2024 ; arXiv, Security Properties of Machine-Generated Code, 2025 ; arXiv, Architectural Drift in AI-Generated Software, octobre 2025 ; arXiv, Iterative Degradation of Security in LLM Code Refinement, mai 2025 ; Mend.io et USENIX, Slopsquatting, 2025 ; Legit Security, False Positive Reduction, 2024 ; GitHub, Enterprise Developer Survey, 2024 ; Gartner, Multi-Agent Systems et AI Orchestration Market, 2025



